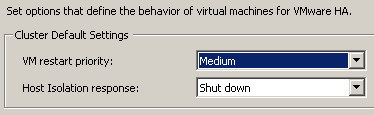
Как вы знаете, в механизме высокой доступности VMware High Availability (HA) есть такая настройка как Isolation Responce, которая определяет, какое событие следует выполнить хосту VMware ESX / ESXi в случае наступления события изоляции для него в кластере (когда он не получает сигналов доступности - Heartbeats - от других хост-серверов).
Leave powered on
Power off
Shutdown
Сделано это для того, чтобы вы могли выбрать наиболее вероятное событие в вашей инфраструктуре:
Если наиболее вероятно что хост ESX отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Но есть еще один момент. Как вам известно, VMware HA тесно интегрирована с технологией VMware Fault Tolerance (непрерывная доступность ВМ, даже в случае выхода физического сервера из строя). Суть интеграции такова - если хост с основной виртуальной машиной выходит из строя, то резервный хост выводит работающую резервную ВМ на себе "из тени" (она становится основной), а VMware HA презапускает копию этой машины на одном из оставшихся хостов, которая становится резервной.
Так вот настройка Isolation Responce не применяется к машинам, защищенным с помощью Fault Tolearance. То есть, если хост VMware ESX с такой машиной становится изолированным, при настройке Power off или Shutdown он такую машину не гасит, а всегда оставляет включенной.
Рекомендация - иметь network redundancy для сети heartbeats. Не должен хост себя чувствовать изолированным, если он весь не сломался.
Копировать руками машину каждый раз, когда нужно внедрить какое-то оборудование, или просто для сохранения данных, это безумно неудобно. Вот для этого и была придумана технология автоматизированного бэкапа, написанная энтузиастами на скриптах perl: ghettoVCB.
Уважаемые коллеги, хочу Вам сообщить, что в организационной структуре VMware Россия и страны СНГ произошли значительные изменения. Во-первых, некоторое время назад пост руководителя группы системных инженеров покинул Дмитрий Тихович (который, помимо всего прочего, поддерживал также официальный блог VMware Russia - http://www.vmware-blog.ru/). Теперь Дима работает в компании Citrix (см. его профиль в LinkedIn) в качестве PAM'а (Partner Account Manager).
Кроме того, вчера стало известно, что пост директора VMware Russia/CIS покинул Антон Антич, работавший в VMware более четырех лет (там же он был директором по партнерам и первым человеком, который пришел в российское представительство VMware). Очевидно, что данные перестановки связаны с коренными изменениями в самой компании VMware на уровне высшего руководства (например).
Что Дмитрий, что Антон - очень приятные и умные люди, с которыми было приятно работать по бизнесу VMware, и которые, наверняка, не оставят отрасль виртуализации в своей дальнейшей деятельности. Желаю вам успеха, коллеги!
Update. Из российского представительства также ушел Виталий Суховский, соратник Антона, отвечавший за продажи VMware в России и СНГ.
Как мы уже писали, в VMware vSphere 4.1 появилась технолония Storage IO Control (SIOC, подробности здесь), которая позволяет настраивать приоритеты доступа виртуальных машин к хранилищам не в рамках одного хоста VMware ESX / ESXi, а в рамках всего кластера.
и какие рекомендации по настройкам Latency можно использовать при борьбе виртуальных машин за ресурсы ввода-вывода, в зависимости от типов хранилищ:
Второй документ называется "Managing Performance Variance of Applications Using Storage I/O Control". Он содержит результаты тестирования SIOC в условиях, когда нужно выделить виртуальную машину как критичную с точки зрения ввода-вывода (отмечена звездочкой). Взяли требовательную к нагрузкам задачу (DVD Store).
Измерили эталонную производительность когда работает только критичная ВМ (левый столбик - принят за единицу, SIOC Off), измерили среднуюю производительность (когда все машины работают параллельно и у каждой Shares установлено в 1000, SIOC Off), а потом стали варьировать Shares для критичной виртуальной машины (при включении SIOC On) смотря на то, как растет ее производительность в рамках кластера:
Видим, что SIOC при распределении приоритета ввода-вывода между хостами работает. В этом же документе есть еще тесты, посмотрите.
Как вы знаете, для виртуальных хранилищ (datastores) в VMware vSphere есть возможность задавать разные размеры блоков тома VMFS. Также вы, вероятно, знаете, что операция Storage vMotion позволяет перемещать виртуальную машину между хранилищами, превращая ее виртуальный диск из толстого (thick) в тонкий (thin).
Но чтобы это результирующий тонкий диск после Storage vMotion занимал на целевом хранилище только столько пространства, сколько используется внутри гостевой ОС (а не весь заданный при создании), нужно предварительно почистить блоки с помощью, например, утилиты sdelete.
Duncan Epping, известный технический эксперт VMware, обратил внимание на проблему, когда пользователь делает очистку блоков, затем Storage vMotion, а уменьшения диска не происходит. Почему так?
Очень просто, в составе VMware ESX / ESXi есть три типа datamover'ов ("перемещателей"):
fsdm – это старый datamover, который представляет собой базовую версию компонента. Он работает сквозь все уровни, обозначенные на картинке. Зато он, как всегда, универсален.
fs3dm – этот datamover появился в vSphere 4.0 и имеет множество оптимизаций. И вот тут данные уже не идут через стек работы с виртуальной машиной. То есть он работает быстрее.
fs3dm – hardware offload – Этот компонент появился для поддержки технологии VAAI, которая позволяет вынести операции по работе с хранилищами виртуальных машин на сторону массива (hardware offload). Он, естественно, самый быстрый и не создает нагрузку на хост VMware ESX / ESXi.
Так вот основная мысль такова. Когда вы делаете миграцию Storage vMotion виртуальной машины между хранилищами с разными размерами блоков используется старый datamover fsdm, а когда с одинаковыми, то новый fs3dm (в программном или аппаратном варианте). Последний работает быстрее, но не умеет вычищать нулевые блоки на целевом хранилище у виртуального диска VMDK.
А вот старый fsdm, ввиду своей универсальности, это делать умеет. То есть, если нужно вычистить нулевые блоки не перемещайте ВМ между хранилищами с одинаковыми размерами блоков. Так-то вот.
Компания VMware на прошедшей конференции VMware Partner Exchange 2011 (PEX) объяивла о некоторых подробностях касательно следующей версии платформы виртуализации VMware vSphere 5.0.
Сначала новые возможности vSphere 5.0:
Dynamic Resource Scheduling (DRS) for Storage - эта давно ожидаемая функция платформы виртуализации, которая позволит автоматически выравнивать нагрузку на системы хранения путем динамического перемещения работающих виртуальных машин между хранилищами (сейчас это можно сделать вручную за счет Storage VMotion). Пользователи смогут определять группы Datastor'ов (они зовутся Storage Pods), которые будут использоваться для балансировки по хранилищам на базе их заполненности. Предполагается, что это повысит автоматизацию датацентров. О балансировке нагрузки по производительности хранилищ пока ничего не говорится.
Host-based replication for Site Recovery Manager - возможность репликации виртуальных машин на уровне хостов а не SAN-хранилищ (как делается сейчас). То есть, поддержка технологии репликации со стороны СХД будет не нужна, репликация будет работать в асинхронном режиме со стороны хост-серверов. По-сути, это аналог репликации виртуальных машин в продукте Veeam Backup and Replication 5, которая сейчас активно используется в производственной среде многими компаниями для защиты данных виртуальных машин и наиболее быстрого восстановления работоспособности сервисов (показатели RTO).
Network I/O control for Virtual Machines - эта возможность будет позволять резервировать часть канала для приоритетных задач в кластере HA/DRS на случай его перегрузки. Актуально это будет для сетей 10G, где канал шире, а вот физических адаптеров значительно меньше.
Выход VMware vSphere 5.0 запланирован на второе полугодие 2011 года. Но скорее всего пятая версия платформы выйдет до VMworld 2011, который начнется 29 августа.
Также на партнерской сессии были озвучены несколько вещей на будущее (2012 год, после vSphere 5) - фреймворк SLA, который будет позволять пользователям внутренних облаков на базе VMware vSphere определять показатели качества обслуживания для своих приложений ("policy engine"). Также обсуждалась доступность в 2012 году стандартной функциональности long-distance vMotion, которая будет позволять перемещать работающие виртуальные машины на большие расстояния (вместе с Cisco VMware делала эксперименты по перемещению на сотни миль). Сейчас Long Distance vMotion уже поддерживается для некоторых сценариев.
Если вы используете пулы типа Linked Clone (на основе базового образа) в решении для виртуализации ПК VMware View 4.5, то знаете, что есть такая операция "Rebalance", которая перераспределяет виртуальные ПК пула по хранилищам VMFS / NFS. Но многие удивятся, как работает эта функция. Например, у вас есть несколько хранилищ различной емкости, и вы делаете Rebalance десктопов.
Получаете вот такую картину:
Слева - то, что вы ожидаете увидеть в результате балансировки, а справа - то, что получается на самом деле. В чем причина?
Все дело в том, что VMware View 4.5 использует для перемещения машин на хранилище параметр "weighted available space". У какого из хранилищ он больше - туда виртуальные машины и переезжают. Что это за параметр:
datastore_capacity - это общая емкость хранилища VMFS / NFS.
virtual_usage - это максимально возможный объем, занимаемый виртуальными машинами на хранилище, который формируется из размера виртуальных дисков машин (номинального, а не реального) + размер памяти (для Suspend).
overcommit_factor - это настройка для Storage Overcommit, которую вы задавали для Datastore, когда выбирали, какие из них следует использовать для пулов Linked Clone. Там были такие значения:
None - хранилище не является overcommitted.
Default - это коэффициент 4 от размера хранилища
Moderate - это коэффициент 7 от размера хранилища
Aggressive - это коэффициент 15 от размера хранилища.
Если вы забыли, где это выставляли, то это вот тут:
Теперь переходим к примеру и формуле. Есть у нас вот такая картинка (см. настройки overcommitment):
Теперь вот вам задачка - что будет в результате Rebalance виртуальных ПК?
По-сути, правило таково: если у вас все хранилища с одинаковым уровнем Storage Overcommitment и одинакового размера, то виртуальные машины будут перемещены на другие хранилища, если там больше свободного места, чем свободного места на текущем хранилище. Ну а если разного размера и одинакового уровня Overcommitment - то ожидайте того, что машины останутся на больших хранилищах. Так-то вот.
И да, никогда не далейте Storage VMotion для виртуальных машин VMware View 4.5 вручную - это не поддерживается со стороны VMware.
Замечательный сайт myvirtualcloud.net опубликовал интересный калькулятор, который расчитывает необходимую ширину канала для пользователей виртуальных ПК VMware View 4.5, использующих свои десктопы по протоколам Microsoft RDP и Teradici/VMware PCoIP. Особенно это актуально для WAN-соединений при работе удаленных пользователей из дома, филиалов, командировок и т.п.
В качестве исходных данных рассматриваются 4 профиля нагрузки - офисные приложения без мультимедиа (тяжелые и легкие нагрузки), а также требовательные мультимедиа-приложения (также легкие и тяжелые). Расчеты основаны на рекомендациях VMware и Teradici и включают в себя необходимые требования ко всем типам трафика: картинка экрана, перенаправление USB, аудиотрафик и данные. Исходные требования таковы:
Ну а вот и сам калькулятор (приятно, что много разных параметров). Тыкаем на картинку:
Какими же новыми способами нам предлагают использовать технологию SureBackup в продукте Veeam Backup and Replication 5.0 для резервного копирования виртуальных машин и репликации:
1. Тестирование безопасности виртуальных машин.
Запускаем виртуальную машину прямо из резервной копии в рамках тестовой лаборатории и делаем penetration test:
Преимущество - на надо насиловать работающую продуктивную систему.
2. Служебные операции с производственными базами данных.
Зачастую, с базой данных нужно произвести некоторые операции, которые не затрагивают операции записи в базу. Их не обязательно делать на продуктивной системе, поскольку это снижает производительность работающей информационной системы. Можно использовать мгновенно запускаемую резервную копию для изменения модели данных или проводить анализ данных (data mining).
3. Тестирование изменений в скриптах PowerCLI.
Например, правила написания скриптов PowerCLI 4.1 заметно отличаются от PowerCLI 4.0, что требует переработки скриптов и их тестирование. А ведь тестировать на продуктивной системе - это моветон. Поэтому делать это можно в изолированной тестовой лаборатории Veeam Backup and Replication 5.
4. Тестирование больших объектов GPO.
В больших организациях системные администраторы часто занимаются разработкой и тестированием новых политик GPO, которые еще неизвестно как лягут на продуктивные системы. Veeam Backup and Replication и его тестовые лаборатории помогут вас в этом и позволят не затронуть продуктивные системы.
5. Тестирование многомашинных приложений.
Это, по-сути, классика Lab Management'а. С помощью виртуальных изолированных лабораторий вы сможете проверять патчи, апгрейды и любые другие изменения в составе многомашинного приложения в независимой от продуктива тестовой среде.
Как видно, это всего лишь некоторые типовые сценарии применения технологии SureBackup в Veeam Backup and Replication 5.0. Всего возможностей, которые он открывает - очень много. Так что, вперед - тестируйте, покупайте, тем более, что продукт пока продается по старым ценам (смешным для средств резервного копирования).
Мы уже писали об интересной бесплатной утилите RVTools для управления серверами виртуализации VMware vSphere и виртуальными машинами. На днях вышла версия RVTools 3.0, в которой появилось множество нововведений и улучшений.
Естественно, RVTools 3.0 поддерживает VMware ESX 4.1 / vCenter 4.1, а также приобрела несколько новых функций:
Новая вкладка с информацией о сервисной консоли и параметрах VMKernel.
Pass-through аутентификация. Можно логиниться на серверы под текущим Windows-аккаунтом.
Числовые колонки корректно отформатированы, значения для размеров снапшотов отображаются в мегабайтах
Поддержка vSphere Web Services SDK 4.1, которые поддерживают новые возможности ESX 4.1
Экспорт в csv теперь учитывает региональные настройки (точки там, запятые)
Можно делать импорт в xls без установленного Excel
Каждая таба при импорте в xls попадает на отдельный лист
Сейчас модно говорить про облачные вычисления и облака. За счет виртуализации эти разговоры становятся реальностью во многих компаниях (частные облака) и у сервис-провайдеров (публичные облака). Есть такой ресурс doublecloud.org, где Steve Jin выкладывает паттерны построения облаков.
Эти паттерны он формализует по определенным правилам и рассматривает проблемы и решения, которые возникают в процессе размышлений над различными аспектами облачной инфраструктуры. Таги: Cloud, Cloud Computing, Enterprise, VMware, VMachines, Blogs,
Компания Veeam даже в январе шевелится, в отличие от остальных тех, кто еще спит. Итак, новостей две. Во-первых, вышла вторая глава книги "The Expert Guide to VMware Data Protection and Disaster Recovery" от Eric Siebert. Глава называется "Backup and Recovery Methodologies":
Часто задаваемый вопрос: можно ли осуществлять резервное копирование виртуальных машин на ESX, работающих в кластере постоянной доступности VMware Fault Tolerance. Ответ прост - согласно ограничениям технологии FT, бэкап таких работающих виртуальных машин делать нельзя, поскольку для них нельзя сделать мгновенный снимок (снапшот).
А ведь, зачастую, пользователям нужна не только высокая доступность сервиса в виртуальной машине на случай аварии или других неприятностей, но и резервное копирование на случай утери критичных данных. Кстати говоря, VMware обещала сделать поддержку одного снапшота для FT-машин в целях резервного копирования, но так и не сделала этого в версии VMware vSphere 4.1. А делать бэкап надо - поэтому придется все делать самим.
Очевидных пути выхода из положения два:
1. Делать резервное копирование данных виртуальной машины средствами гостевой ОС (копирование на уровне файлов) либо средствами SAN (снапшоты).
2. На период бэкапа (например, средствами Veeam Backup) выключать защиту Fault Tolerance для виртуальной машины вручную или с помощью скрипта по расписанию. Этот способ подходит не всем, поскольку на время резервного копирования машина оказывается незащищенной.
О первом способе вы и так знаете, поэтому поговорим о втором:
Затем минут за 10-15 до запуска задачи резервного копирования отключаем Fault Tolerance для машины командой (ее можно добавить в bat-файл и запускать планировщиком):
Затем запускаем задачу резервного копирования Veeam Backup, в настройках которой есть замечательный параметр для выполнения скрипта после завершения задачи:
А вот в этом батнике мы уже снова включаем Fault Tolerance командой вроде этой:
Понятное дело, что данный способ является костылем, и скорее всего данная особенность будет исправлена в следующей версии vSphere, но пока приходится делать вот так.
Таги: VMware, FT, Backup, Fault Tolerance, vSphere, ESX, Blogs, HA
Хорошая статья "Optimising PCoIP Display & Imaging" появилась на сайте myvirtualcloud.net. Ее основная суть - как с помощью групповых политик можно управлять различными параметрами PCoIP в целях оптимизации производительности виртуальных ПК VMware View 4.5. Особенно актуальны эти настройки для WAN-соединений, где PCoIP в сравнении с тем же Citrix HDX/ICA показывает не самые лучшие результаты.
Вот каких параметров можно добавить в реестр виртуальной машины VMware View (тип REG_DWORD) и через групповые политики:
PColPMaxLinkRate GPO (pcoip.max_link_rate)
Это значение максимальной ширины канала для сессии PCoIP в килобитах в секунду. По умолчанию это значение в 1 Gbps. Значение 0 - отменяет ограничения по ширине канала.
По умолчанию установлено значение в 30 кадров в секунду (fps). Это основной параметр, который следует регулировать в окружениях, ограниченных по пропускной способности канала. Если у вас канал очень узкий, а машин в него должно влезть много - регулируйте максимальное число кадров в секунду (но про качество картинки тоже не забывайте). На практике одна машинка без видео и других тяжелых для VDI нагрузок кушает где-то 200-300 Kbps.
Обнаружилась интересная бесплатная утилита HyperV_Mon, которая позволяет наблюдать за производительностью серверов Microsoft Hyper-V и своевременно обнаруживать проблемы:
HyperV_Mon 1.8 показывает ресурсы (CPU, Memory, I/O), используемые root partition и гостевыми системами виртуальных машин, а также накладные расходы гипервизора. Версия 2.0 будет поддерживать уже Hyper-V R2, который будет в Windows 2008 R2 SP1, планируемый к релизу в ближайшее время. Скачать HyperV_Mon 1.8 можно по этой ссылке.
Мы уже писали о продукте для виртуализации корпоративных приложений VMware ThinApp (здесь и здесь), который может быть использован как в рамках решения VMware View 4.5 для виртуализации корпоративных ПК предприятия, так и самостоятельно.
Sven Huisman, один из авторов портала virtualfuture.info, сделал интересный документ "How to deploy your ThinApps?", в котором детально описываются варианты развертывания виртуализованных приложений VMware ThinApp в корпоративной среде (пошагово и с инструкциями). Как вы знаете, у ThinApp нет собственного механизма развертывания виртуализованных приложений (централизованное развертывание есть только в консоли VMware View), поэтому этот документ может оказаться весьма полезным:
Таги: VMware, ThinApp, Blogs, View, Whitepaper, Обучение
Как обычно, Duncan Epping написал отличный пост об использовании памяти виртуальными машинами на хостах VMware ESX. Постараемся объяснить это на русском языке. Итак, если открыть вкладку Summary в vSphere Client для виртуальной машины, мы увидим вот такую картину:
Здесь есть 2 главных параметра:
Memory - это то количество оперативной памяти, которое вы выделили виртуальной машине при создании. За это количество гостевая ОС не выйдет при ее использовании. Это же количество памяти вы увидите в гостевой ОС.
Memory Overhead - это количество памяти, которое может потребоваться гипервизору на поддержание работы виртуальной машины сверх используемой памяти (т.е. расчетные накладные расходы на виртуализацию, но не текущие).
Далее мы видим панель Resources, здесь есть такие показатели:
Consumed Host Memory - это количество физической памяти хоста ESX, выделенной виртуальной машине. Обычно это значение не больше значения Memory на предыдущей картинке. Но может быть и больше, поскольку Consumed Host Memory включает в себя и Memory Overhead, но не с картинки выше, а реально используемый гипервизором Overhead (о котором будет идти речь ниже). И важный момент - счетчик Consumed для Memory на вкладке "Performance" не включает в себя Overhead.
Active Guest Memory - это количество памяти, которое по мнению гипервизора VMkernel активно используется гостевой операционной системой. Вычисляется этот параметр на базе статистических показателей. То есть, если ОС не очень активно использует память, то можно ей ее немного подрезать в условиях нехватки ресурсов.
Теперь идем на вкладку "Resource Allocation". Здесь все немного сложнее:
Появляются вот такие показатели:
Для Host Memory (видим, что это 2187 МБ = сконфигурированная память 2048 МБ + Overhead):
Consumed - это, опять-таки, объем потребляемой виртуальной машиной физической памяти хоста ESX (постоянно меняется). И он включает в себя накладные расходы гипервизора по памяти.
Overhead Consumption - это текущий объем затрат памяти на поддержание виртуальной машины (здесь 42 МБ в отличие от расчетного в 110 МБ)
А формула такова: Consumed = Private + Overhead Comsumption
Для Guest Memory (2048 МБ сконфигурировано в настройках):
Private - это объем памяти физически хранимый хостом для виртуальной машины (см. формулу выше).
Shared - это объем памяти, который отдается другим виртуальным машинам от разницы между сконфигурированным объемом (Configured Memory) и потребляемым (Consumed). Суть в том, что ОС Windows при загрузке очищает всю память виртуальной машины, но потом эти пустые страницы приложениями не используются. Поэтому гипервизор отдает их другим ВМ, пока ВМ, владеющая памятью не потребует их. Эти страницы и есть Shared. Как мы видим, Private + Shared = Guest Memory.
Swapped - это объем памяти, ушедший в файл подкачки vswp. То есть это не файл подкачки Windows, а файл подкачки в папке с виртуальной машиной. Само собой этот показатель должен быть нулевым или совсем небольшим, поскольку своппинг, который делает ESX (а точнее VMkernel) - это плохо, т.к. он не знает (в отличие от Windows), какие страницы нужно складывать в своп, поэтому кладет все подряд.
Compressed - это объем памяти, который получен после сжатия страниц с помощью механизма Memory Compression (то есть, хранимый в VM Compression Cache).
Ballooned - это объем памяти, который забрал balloon-драйвер (vmmemctl), чтобы отдать ее другим нуждающимся виртуальным машинам.
Unaccessed - это память, к которой гостевая ОС ни разу не обращалась (у Windows - это близко к нулю, так как она обнуляет память при загрузке, у Linux должно быть как-то иначе).
Active - опять-таки, активно используемая память на основе статистики гипервизора.
На хорошем и производительном хосте VMware ESX метрики Compressed, Ballooned, Unaccessed - должны быть около нуля, так как это означает что машины не борются за ресурсы (то есть не сжимают страницы и не перераспределяют память между собой). Ну и, конечно, если показатель Active маленький, стоит задуматься об урезании памяти (но сначала посмотрите в гостевую ОС, она лучше знает, чем гипервизор, все-таки).
Worst Case Allocation - это сколько будет выделено виртуальной машине при самом плохом раскладе (максимальное использование ресурсов), то есть вся память будет использоваться, да еще и накладные расходы будут (т.е., Configured + максимальный Overhead).
Overhead Reservation - это сколько зарезервировано памяти под Overhead гипервизором.
Вне зависимости от издания VMware ESXi 4.1 (будь то бесплатная версия, или лицензия Enterprise Plus), доступна функция Configuration-Software=-Virtual Machine Startup/Shutdown (рис.1), которая позволяет отработать ситуацию с выключением питания на физическом сервере и автоматически запускает виртуальные машины... Таги: VMware, VMachines, vSphere, Script, Blogs, HA
Помните мы писали о замечательном человеке Романе, который делает переводы технических документов NetApp, которые дают много полезной информации не только пользователям СХД этого вендора, но и раскрывают общие принципы использования хранилищ для физической и виртуальной инфраструктуры.
А вот что есть еще интересного о виртуализации на русском языке (остальное - здесь):
Использование NFS в VMware Bikash Roy Choudhury | NetApp | Июль 2010 | TR-3839 В данном документе рассматриваются потенциальные преимущества использования в инфраструктуре хранения VMware работы по Network File System (NFS) с системы хранения NetApp®. Скачать .pdf(22 страницы) html
Интеграция NetApp с VMware vStorage API Robert McDonald | NetApp | Июль 2010 | WP-7106 Этот документ описывает набор поддерживаемых в NetApp средств VMware® vStorage APIs for Array Integration (VAAI). VAAI это набор API, позволяющих виртуализованной инфраструктуре на базе VMware vSphere™ тесно интегрироваться с системой хранения. Скачать.pdf (8 страниц)
Наилучшие методы использования систем хранения NetApp для решений виртуализации Microsoft Hyper-V Chaffie McKenna, NetApp | Ravi B, NetApp | Декабрь 2009 | TR-3702-1209
Этот документ содержит руководство и описание наилучших методов для построения интегрированной архитектуры и внедрения Microsoft Hyper-V с использованием систем хранения NetApp. Технологии NetApp, рассматриваемые в этом руководстве важны для создания эффективного с точки зрения затрат, производительности, гибкости и дружественности к окружающей среде интегрированного решения хранения данных виртуальной серверной инфраструктуры. Скачать .pdf (105 страниц)
Руководство по наилучшим способам использования систем NetApp с VMware Virtual Infrastructure 3 M. Vaughn Stewart, Michael Slisinger, Larry Touchette, | NetApp | TR 3428
Перевод Р. Хмелевского Данный документ рассматривает наилучшие методы решений при внедрении VMware Virtual Infrastructure с использованием системы хранения Network Appliance FAS. Полезные советы, особенности установки и настройки, как на стороне системы хранения, так и на стороне VMware ESX/VI. Скачать.pdf (76 страниц)
В решении для виртуализации настольных ПК предприятия VMware View 4.5 доступ к виртуальным компьютерам на серверах VMware ESX происходит с помощью VMware View Client 4.5. У этого клиента есть несколько интересных параметров командной строки, которые можно задавать в свойствах ярлыка wswc.exe, делающих инфраструктуру доступа более гибкой.
-serverURL XXX - URL сервера View Connection Server
-logInAsCurrentUser XXX - вход как current user (true или false)
-unattended- старт в режиме unattended mode (без взаимодействия с пользователем)
-connectUSBOnStartup XXX - проброс всех USB в виртуальный ПК при запуске клиента (true или false)
-connectUSBOnInsert XXX - проброс устройства USB в виртуальный ПК, когда новое устройство втыкается в рабочую станцию (true или false)
-printEnvironmentInfo - вывести информацию о системе
-rollback - откат десктопа для Local Mode (нужен параметр -desktopName)
-standalone- не поддерживается!: запуск еще одной копии View Client для тестирования
-confirmRollback - подтверждение операции rollback для неинтерактивного режима (non-interactive mode)
-? - Показ помощи с данными командами
Кроме того, при установке клиента VMware View Client 4.5 можно использовать следующие параметры (например, при запуске файла VMware-viewclient-x86_64-4.5.0-293049.exe):
INSTALLDIR=%ProgramFiles%\VMware, Inc.\VMware View\Client VDM_SERVER=<IP-Address> или FQDN-имя DESKTOP_SHORTCUT=0 (0=не создавать иконку на рабочем столе, 1=создавать) QUICKLAUNCH_SHORTCUT=0 (0=не создавать иконку в панели быстрого запуска, 1=создавать) STARTMENU_SHORTCUT=0 (0=не создавать пункт в меню "Пуск", 1=создавать) REBOOT="ReallySuppress" (не перезагружать компьютер по окончанию установки)
Кроме этих свойств, можно также выбирать компоненты, которые будут установлены в VMware View Client. Их кодовые названия: Core, MVDI, ThinPrint, TSSO, USB. Само собой, компонент "Core" - обязателен. Можно использовать также ключ ALL для установки всех комонентов.
ADDLOCAL=Core, MVDI, ThinPrint, TSSO, USB или просто ALL
Расшифровка:
Core = ядро MVDI = поддержка Local Mode (если есть в дистрибутиве) ThinPrint = возможность Universal Printing (Print redirection) TSSO = Сквозной логин (Single Sign-On) USB = Перенаправление USB-устройств (USB Redirection)
Штука очень классная. Чтобы ее сделать, компания Veeam наняла независимую исследовательскую компанию Vanson Bourne, которая опросила 500 ИТ-директоров крупных компаний (в каждой из которых работает больше 1000 человек).
Вот что они говорят:
Восстановление виртуальной машины занимает до 5 часов (!)
59% организаций до сих пор используют продукты для резервного копирования, которые применяются и для физической среды (что плохо, так как они не выполняют специфических для виртуализации задач)
63% испытывают проблемы ежемесячно, когда пытаются восстановить виртуальный сервер сервер
Например, вот основные выгоды, которые получают компании от виртуализации. Заметьте, что повышение эффективности защиты данных далеко не на последнем месте:
А вот какая часть инфраструктуры виртуализована сейчас и сколько будет через 2 года:
Мы уже писали о команде esxtop для серверов VMware ESX, которая позволяет отслеживать основные параметры производительности хост-сервера и его виртуальных машин. Duncan Epping недавно добавил еще несколько интересных моментов в свое руководство по работе с утилитой esxtop, некоторые из которых мы сейчас опишем.
Итак:
1. Для того, чтобы использовать пакетный режим работы esxtop (batch mode), нужно использовать ключ -b:
esxtop -b >perf.txt
Это позволит вывести результаты команды esxtop в файл perf.txt. Для задания числа хранимых итераций используйте ключ -n (например, -n 100).
Очень удобно для сбора исторических данных производительности на хосте VMware ESX.
2. Контролируйте счетчик %SYS - он показывает загрузку системных ресурсов хоста (в процентах). Рекомендуется, чтобы он не превышал 20 для системных служб.
3. Для установки частоты обновлений результатов esxtop используйте клавишу <s>, далее задавайте интервал в секундах:
В пакетном режиме этот интервал задается ключом -d (например, -d 2).
4. Для отслеживания метрик конкретной виртуальной машины можно ограничить вывод конкретным GID. Например, чтобы посмотреть ВМ с GID 63, нажмите клавишу <l> (list) и введите этот GID:
5. Чтобы ограничить количество выводимых сущностей, используйте клавишу <#>. Например, можно сделать вывод первых 5:
И сами кнопки в режиме работающей esxtop:
c = cpu
m = memory
n = network
i = interrupts
d = disk adapter
u = disk device (включая NFS-девайсы)
v = disk VM
y = power states
V = показывать только виртуальные машины
e = раскрыть/свернуть статистики CPU для конкретного GID
k = убить процесс (только для службы техподдержки!)
l = ограничить вывод конкретным GID (см. выше)
# = ограничить число сущностей (см. выше)
2 = подсветка строчки (двигает фокус вниз)
8 = подсветка строчки (двигает фокус вверх)
4 = удалить строчку из результатов вывода
f = добавить/удалить колонки
o = изменить порядок колонок
W = сохранить сделанные изменения в файл конфигурации esxtop
? = помощь для esxtop
На прошедшей недавно в Берлине конференции Citrix Synergy компания Citrix официально объявила о выпуске новой версии продукта для виртуализации настольных ПК предприятия XenDesktop 5.
Напомним, что на сегодняшний день решение Citrix XenDesktop является лидирующим продуктом на рынке VDI (Virtual Desktop Infrastructure). Кроме того, Citrix XenClient, интегрированный с XenDesktop, является единственным на сегодняшний день "клиентским гипервизором", который позволяет распространять виртуальные машины пользователей на устройства без операционной системы (bare-metal гипервизор).
В Citrix XenDesktop 5 появился новый компонент - Citrix Desktop Director. Это веб-консоль, представляющая собой единую точку управления и контроля инфраструктуры виртуальных ПК, которая оказывает существенную помощь при решении типичных проблем в крупных организациях.
Новые возможности Citrix XenDesktop 5 рассмотрены в статье "Citrix Accelerates Virtual Desktop Revolution with XenDesktop 5". Стоимость Citrix XenDesktop 5 для издания VDI-only (без XenApp) составит $95 (на одного пользователя или устройство). Цена XenDesktop 5 Enterprise и Platinum Edition будет составлять $225 и $350 соответственно.
На данный момент Citrix XenDesktop 5 недоступен для загрузки. Выпуск продукта намечен на четвертый квартал этого года. Как только выйдет финальный релиз продукта, мы обязательно детально рассмотрим его новые возможности в отдельной статье.
Данная статья основывается на инструкции, написанной Joseph Holland, Kepak Group «How to configure VMWare ESXi to shutdown using an APC SmartUPS. v3.0_20090312», и является ее переработанным и дополненным переводом. Для настройки интеграции UPS APC и VMware ESXi понадобится установленный виртуальный модуль vMA.
Компания VMware анонсировала новый онлайн-сервис Product Interoperability Matrix, который позволяет проверить совместимость различных версий продуктов между собой.
Например, выбираем VMware ESX версии 4.1 и VMware vCenter - получаем результат в таблице, по которому видно, что для ESX 4.1 подходит только vCenter 4.1 (но не наоборот! - потому что vCenter 4.1 может управлять даже ESX 3.5 Update 5).
На сайте myvirtualcloud.net появилась отличная статья, в которой описываются подходы к отказоустойчивости и восстановлению после сбоев (Disaster Recovery) в инфраструктуре виртуальных ПК VMware View 4.5.
Рассматриваются конфигурации Active-Active и Active-Passive для сайтов, где развернуто решение VMware View. Статья обязательна к ознакомлению тем, кто еще не задумывался над этим важным вопросом.
Когда произносится слово «виртуализация», сразу на ум приходят названия фирм VMware, Microsoft, Cisco… и разных продуктов стоящих за этими фирмами.
Виртуализация в нашем сознании прочно связана с понятиями гостевых ОС, гипервизорами, облачными вычислениями и прочими сложными программными комплексами. Мы уже привыкли, что все связанное с виртуализацией сложно, непонятно, имеет громоздкую программную инфраструктуру и создание таких систем - это удел крупных фирм, обладающих штатом программистов измеряемых сотнями, если не тысячами человек. Однако это всего лишь миф...
Книга действительно интересная, там есть о чем почитать и для новичков, и для продвинутых пользователей: обзор технологии виртуализации VMware, типы файлов и виртуальных дисков виртуальных машин vSphere, обзор методик резервного копирования, репликации и многое другое. Пока доступна только одна глава, но, будем надеяться, скоро будет еще.
Многим из вас, конечно же, давно знакома компания StarWind, делающая отличный продукт StarWind iSCSI Target, который позволяет превратить обычный сервер или недорогую систему хранения данных в надежное отказоустойчивое хранилище для виртуальных машин VMware vSphere или Microsoft Hyper-V.
У меня для вас приятная новость - поскольку StarWind теперь является официальным спонсором портала VM Guru, то вам, уважаемые читатели, теперь будет доноситься гораздо больше свежей, актуальной и детальной информации о продуктах этого вендора. И да, на VM Guru теперь есть раздел о StarWind (его вы видите в верхнем меню).
Что можно сказать о StarWind? Мы берем в свои рекламодатели только лучшие компании, делающие уникальные продукты для оптимизации ИТ-инфраструктуры предприятий. И StarWind - одна из них. Решение iSCSI Target - вообще безальтернативный продукт для стремительно растущего рынка виртуализации и его клиентов. О нем мы уже писали в статье "Как работает StarWind Enterprise HA - отказоустойчивое хранилище для VMware vSphere / ESX" - мы его используем каждый день в наших лабораториях, мы его устанавливаем клиентам, мы его настоятельно предлагаем покупать и некоторое его количество мы уже продали.
Но это мы делали и раньше. А вот начиная с нынешнего момента, мы будем вас посвящать в технические детали работы решений StarWind. Флагманский продукт компании - StarWind Enterprise HA позволяет сделать недорогую отказоустойчивую систему хранения из двух узлов, что защитит диски ваших виртуальных машин в случае выхода из строя одного из хранилищ. Переключение на резерв произойдет мгновенно - без потери каких бы то ни было данных. Это нужное решение и главная фишка в том, что оно недорогое, а каждая компания сможет себе выбрать подходящее издание.
Также есть еще масса интересных возможностей для создания хранилищ виртуальных машин на серверах VMware ESX и Hyper-V:
Синхронное зеркалирование данных: зеркалирование данных в режиме реального времени через кластер хранения, состоящий из двух узлов
Сервер кластеризации: обеспечивает общее хранилище для кластеризации серверов c высокой доступностью
Тонкое резервирование: распределяет пространство динамично для высокоэффективного использования дисковых ресурсов
И бонус: сотрудники StarWind говорят по-русски, поэтому вы всегда сможете быть уверены, что вам помогут, а не будут бормотать в трубку что-то непонятное.
Теперь пул рекламодателей VM Guru окончательно сформирован, так что если хотите купить рекламу на VM Guru - обращайтесь, конечно, но придется обождать.

 RSS
RSS